
AI That Will Identify A tumor
An Artificial Intelligence That Will Identify if a tumor is Malignant or Benign
Blog Post by Jerwell Savella - Published at 11/17/2022
This is How I built an Artificial Intelligence that can Identify if a tumor is Malignant or Benign. For clarification, I do not have any prior education in machine learning from any university, and these are just some of the things I built while learning the concept behind machine learning and artificial intelligence on my own. This is documentation of how I made it; it is by no means a guide. or a tutorial.
They're basically two types of tumors, "Malignant and Benign". Tumors that are malignant are cancerous and might have the potential to spread to nearby organs, glands, and tissue. Even after treatment, cancerous tumors may grow back (cancer recurrence). It may be fatal to have this kind of tumor.
On the other hand, Non-cancerous benign tumors provide little to no risk in our lives. Due to their limited nature, they usually don't spread to other bodily areas or impact nearby tissue. Treatment is not often necessary for benign tumors. However, certain non-cancerous tumors push against other body parts and require medical attention.
From the dataset we provided, having 1 indication in the diagnosis means the tumor is malignant and 0 means the tumor is benign, (For Radiologist this is a very important part of their job because they have to make sure whether or not what they see on the mammogram, or whatever is actually going to be a malignant tumor, so having AI helps radiologists, and this effort might be important and can potentially save other people lives.)
Creating our AI Model
Download the dataset named cancer.csv. This is a real dataset with data from actual tumors. We have a Diagnosis, along with a bunch of numerical attributes relating to different tumors that may or may not be life-threatening.
1. The First thing that we need to do is we need to import our dataset to manipulate the data we got from the actual list of diagnosis.
```python
import panda as pd dataset = pd.read_csv('cancer.csv')
```
2. Next, we need to set up our x and y attributes, The y-attributes will be the one to predict the status of the tumors, and the x-attributes is going to be all of the other characteristics that we need in order for us to map the correlations of our AI algorithm between different features. This will allow Artificial Intelligence to predict whether a tumor is malignant or benign.
```python
x = dataset.drop(colums =["diagnosis(1=m, 0=b)"])
```
- When we're "dropping" what we're basically doing is removing a column, in this case, we're dropping the column which has a diagnosis indication.
- What we've done here is indicated our x attribute to be equal to everything in the dataset except for this diagnosis column.
```python
y = dataset["diagnosis(1=m, 0=b)"]
```
- While for the y column, all we've done here is we're grabbing the diagnosis field that we've dropped from the x attribute.
3. We now established our X and Y column, Now, we need to split up our data between a training set and a testing set, and this is something that's really important in artificial intelligence because oftentimes you'll find some algorithms are "overfitting" which means that they do really well on the data they've already seen that's going into the algorithm but when you give them new data they just fall apart or the accuracy percentage will drop significantly.
So in order to mitigate this, what we're going to do is we're going to set apart our dataset aside to be tested later with our algorithm, So by the time our algorithm has given different data that's never seen before, it will use how well it does on that data evaluation to the current. Because that's actually what we are looking for, not how well this algorithm understands the entire dataset, but more just the problem in general which in our case is "cancer diagnosis".
```python
from sklearn.model_selection import train_test_split x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.2)>)
```
- "Scikit-learn/sklearn" is a popular machine learning library for python, however, on this one, we're actually gonna be using another library mainly. We just used scikit-learn to split our dataset between a training set and a testing test.
- 80:20 is a normal way to divide things up, so 20 percent of our data is going to be in our testing set.
4. This is the time that we are going to build our artificial intelligence, We are gonna be using "TensorFlow - Keras" which is one of the most popular open-source libraries that is used for machine learning and artificial intelligence. One of the things that we're going to be building is the "Neural Network" which is a very popular form of Artificial Intelligence that can be used to teach computers to process data in a way that is inspired by the human brain or type of machine learning process, called deep learning, that uses interconnected nodes or neurons in a layered structure.
- First, we will import TensorFlow as tf and call out Keras as our model.
```python
import tensorflow as tf model = tf.keras.models.Sequential()
```
5. Next, we will start adding layers to our modules. If we look up a Neural Network (show Neural Network picture), We have an "Input Layer" which is our x_values, all of the different attributes of the cancer dataset, and then it goes through the "Hidden Layer" and then finally we have an "Output Layer" which would tell us if our tumor is malignant or benign.
```python
model.add(tf.keras.layers.Dense(256, input_shape=x_train.shape[1:], activation = 'sigmoid')) model.add(tf.keras.layers.Dense(256, activation='sigmoid')) model.add(tf.keras.layers.Dense(1, activation='sigmoid'))
```
- Dense is one of the standard or default neurons that you get in Keras. We also indicated the number of units we want which in our case is just a random power of 2. We made our neural network 256 which is really large, larger than it use to be, just to sort of see how powerful we can get to this dataset.
- We input something with the size of our x_train.shape which is all of our x features or columns in our dataset and then the output will be 256 Neurons,
- We also need an Activation function which we set to sigmoid. All the sigmoid function is like this, what we are going to do is we're gonna take all the values from Neural Network and plot them between 0's and 1's, and this will gonna be very helpful for producing model complexity and also making our model more accurate.
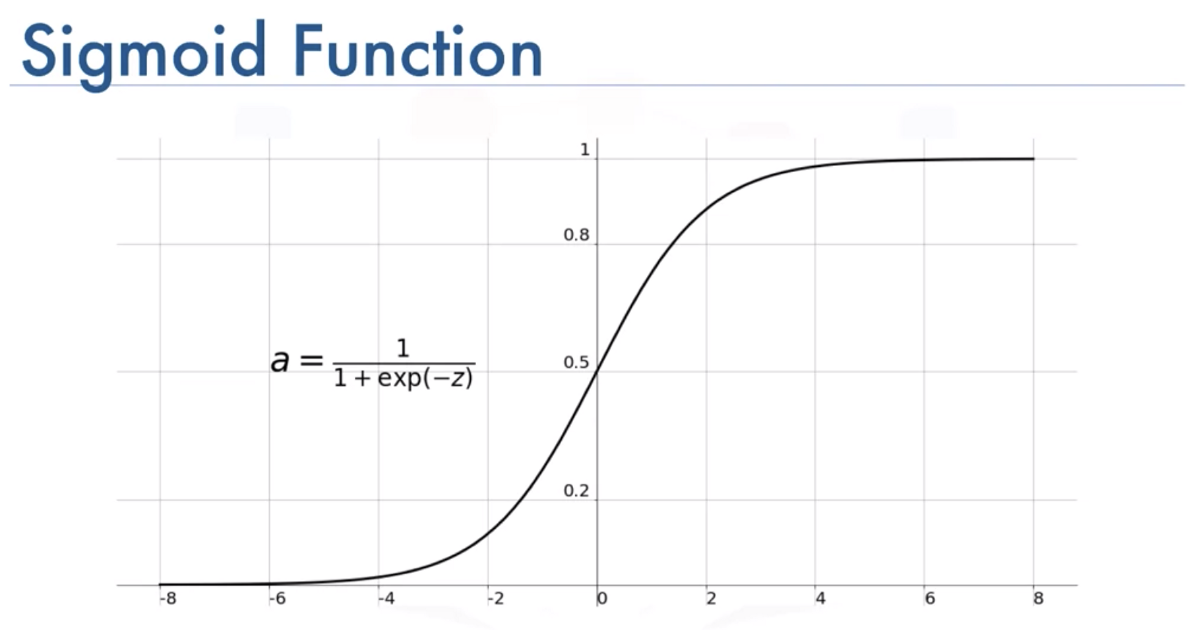
6. Next step is we need to compile our model.
```python
model.compile(optimizer='adam', loss='binary_crossentropy', metrics=['accuracy'])
```
- We used the "Adam optimization algorithm" for deep learning, You can see more information on how this actually works but this is basically how the machine learning algorithm is being optimized or how the neurons and weight of the algorithm are being fine-tuned to fit the data.
- We also used the "loss" function because we're doing binary classification using a metric called "binary cross-entropy". this is really ideal when we are talking about categorical objects or just discrete values.
- And finally, the metric that we're gonna be looking into is "accuracy", because we want to correctly classify as many "tumors" as possible.
7. The next step is to fit our data. We set the number of epochs to a thousand. The number of "epochs" is a hyperparameter that defines the number of times that the learning algorithm will work through the entire training dataset. This is the number of times our algorithm will iterate over the same data we provided.
```python
model.fit(x_train, y_train, epochs=1000)
```
- Having a thousand epochs is kind of a lot since our dataset is small. Most likely because the size of our neural network is very large compared to the size of the problem, this is usually a bit overkill, but it's better to be safe than sorry.
8. Now as we can see in training our AI model, we have the loss function, the accuracy also the Epoch that is on. The accuracy from the start till the end fluctuates quite a bit but it stays consistently above 95 percent for the training set.
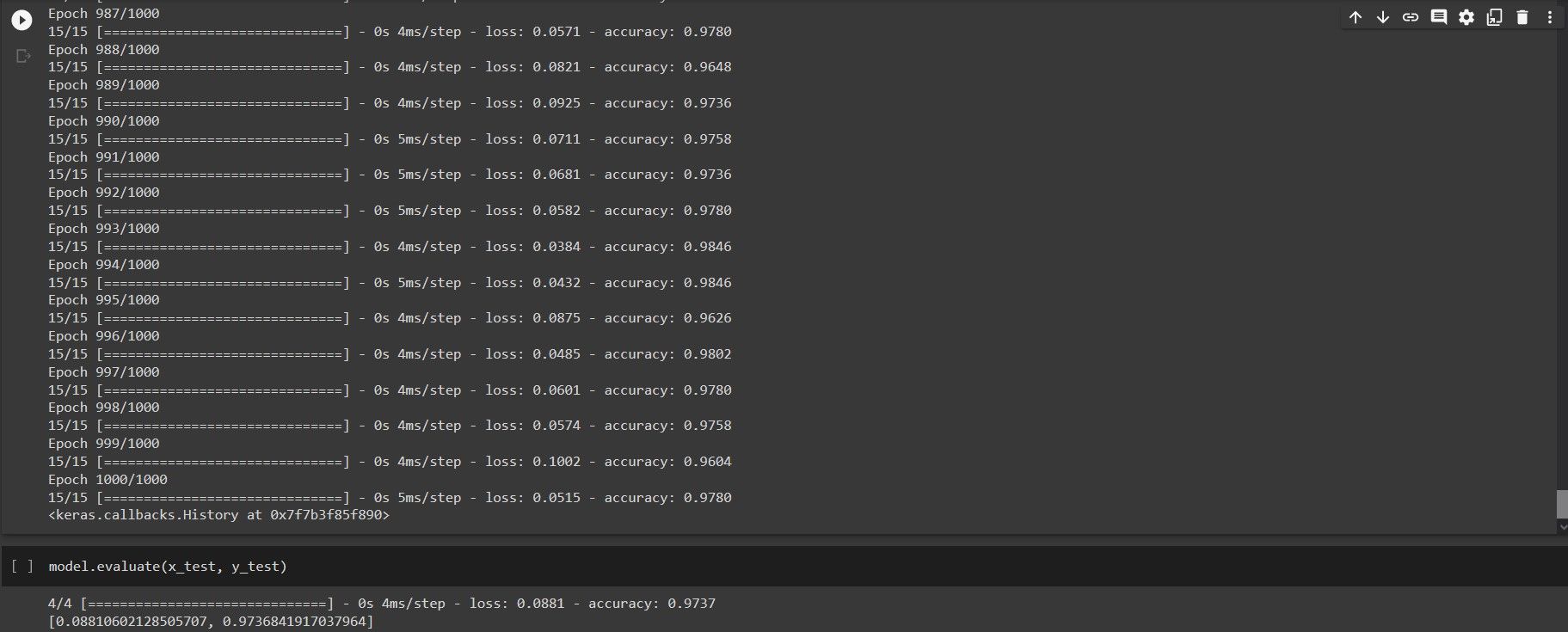
9. We will now evaluate the algorithm we created, We compared here what the model thinks that the y-test should be versus what the y-test actually is.
```python
model.evaluate(x_test, y_test)
```
- By evaluating our machine learning algorithm, we saw that it has 97% accuracy which means it can correctly classify a tumor between cancerous and non-cancerous one. It is really amazing knowing that this Artificial Intelligence can find a pattern using the dataset we provided to categorize whether a tumor is malignant or benign.